xunsearch全文搜索引擎的实际应用,关键代码示例
- 作者: 刘杰
- 来源: 技术那些事
- 阅读:1663
- 发布: 2025-08-21 07:48
- 最后更新: 2025-08-21 08:10
折腾了几天,终于搞定了网站v2版本的升级,首先实现的首页的升级,增加了搜索功能。期间还解决了一些其他问题,比如如何让多套模板,和相应的静态资源文件共存,且互不影响。这样可以保证新版页面和旧版使用了完全不同的js、css 文件,但是却可以通过共同的加载功能加载,极大复用代码。
今天要聊的主题是,如何将 xunsearch 服务,应用到自己的项目中。配置文件的生成之前已经有过详细介绍的文章,可以参见 xunsearch配置文件详解,实例讲解,官网文档看不懂的看这个 这篇文章。
正式进入代码讲解前,先讲一个细节。xunsearch 服务,服务端,理论上安装好就没有什么其他配置了,就可以直接用了。至于项目库的配置、端口设置、自定义分词等等,客户端的 PHP sdk 就能完成。所以理论上,只要将项目配置文件,比如 test.ini 放置到客户端服务器上就可以了。
下边来举例说明下索引服务的生成、更新、删除操作:
php
// 这里根据需要,如果在sdk 的目录可以简写项目的名称,如果在其他位置,直接写 test.ini 的文件路径即可
$index = new XS('test')->getIndex();
// 这里根据配置文件,完全填写好就行
$data = array(
'id' => 'xxxxxxxx'
'title' => '测试文档的标题',
'content' => '测试文档的内容部分',
);
// 创建文档对象
$doc = new XSDocument();
$doc->setFields($data);
// 添加到索引数据库中
$index->add($doc);
// 更新已有的文档,没有的话会自动添加新内容
$index->update($doc);
// 删除主键值为 123 的记录
$index->del('123');
// 批量删除主键值为 1, 2, 3 的记录
$index->del(['1', '2', '3']);
// 删除字段 subject 上带有索引词 `代码` 的所有记录
$index->del('代码', 'subject');
// 删除字段 subject 上带有索引词 `vue`或者`php` 的所有记录,注意,是或者,也就是并集。
$index->del(['vue', 'php'], 'subject');
每次重新生成索引前,需要清空索引:
php
// 获取索引管理对象
$index = new XS('test')->getIndex();
// 执行清空操作
$index->clean();
// 然后重新执行添加文档操作
$doc = new XSDocument();
$doc->setFields([
'id' => 'xxxx',
'title' => '这里是文章的标题',
'content' => '这里是所有要检索的内容'
]);
// 注意,如果数据比较多,$doc 可以通过 clone 来复制,原型模式,减少new 带来的时间消耗。
$index->add($doc);
平滑重建索引,这种方式实际是生产环境需要重建索引时候需要的。上边的删除索引然后重新添加的方式,适用于项目小数据量少,重建索引非常快的时候。比如,几千条数据,反正重新跑索引很快,用时很短,比如几秒钟。如果索引数据比较多,几十万,跑一次需要十几分钟半个小时,那么最好还是建议用平滑重建索引。
平滑重建索引,它的内部实现 相当于在一个临时区域开辟新库,把所有的添加操作全部更新到新库,直到您完成重建,完成后 再用新库替代旧库用于搜索。
这种方式重建时候,不会影响用户的正常使用,用户一直都是可以访问数据的。不像直接删除索引这种,删除后,前端用户就会搜不到任何内容,体验非常不好。如果重建在很慢,那么就会导致,用户一段时间无法使用搜索服务,这个在生产环境是不允许的。
php
// 获取索引对象
$index = new XS('test')->getIndex();
// 宣布开始重建索引,创建一个临时库用来存放搜索数据
$index->beginRebuild();
// 然后在此开始添加数据,会有循环添加的逻辑
...
$index->add($doc);
...
// 告诉服务器重建完毕,将临时库更名为正式库,完成替换
$index->endRebuild();
// 如果重建过程出现异常,比如:DB has been rebuilding
// 这时可以重新跑代码,beginRebuild 会清除之前的错误,也会清除之前未完成的数据,重新重建索引
// 也可以调用 stopRebuild 清除错误,然后在重建 beginRebuild(重建会删除之前未完成数据)
利用缓冲区重建索引,缓冲区的作用,积累到一定程度的数据,然后发送到服务器,可以减少网络传输中的反复的连接、断开网络。增加网络 io 的效率。
php
// 获取索引对象
$index = new XS('test')->getIndex();
// 开启缓冲区,默认 4MB,如 $index->openBuffer(8) 则表示 8MB
$index->openBuffer();
// 在此进行批量的文档添加、修改、删除操作
...
$index->add($doc);
...
$index->del($doc);
...
$index->update($doc);
...
// 关闭缓冲区,必须和 openBuffer 成对使用,会将最后一波数据刷新到服务器
$index->closeBuffer();
注意,不要用多进程或者多线程、或者协程,去同时操作一个服务端连接。这样传输数据时候会导致数据写入错乱。
检索代码也很简单,这里给个示例
php
$search = new XS('test')->getSearch();
$keywords = '前端 vue框架';
$pageSize = 10;
$page = 1;
// 设置搜索词,和结果的分页,获取结果文档
$docs = $search->setQuery($keywords)
->setLimit($pageSize, ($page - 1) * $pageSize)
->search();
// 获取最近的匹配结果
$total = $search->getLastCount();
// 获取和搜索词相关的词 10 个并打印出来
$search->getRelatedQuery($kewords, 10);
foreach ($related as $word) {
echo $word. PHP_EOL;
}
获取热门搜索词:
php
// 获取前 10 个上周热门词
$words = $search->getHotQuery(10, 'lastnum');
// 获取前 10 个本周热门词
$words = $search->getHotQuery(10, 'currnum');
// 获取前 6 个总热门搜索词(默认值是6,可以通过设置此值,获取指定的热词个数)
$words = $search->getHotQuery();
// 热词结果结构与相关词不同
foreach ($words as $word => $count) {
echo $word. '搜索指数为:'. $count. PHP_EOL;
}
以上代码就是实际项目中会用到的代码。
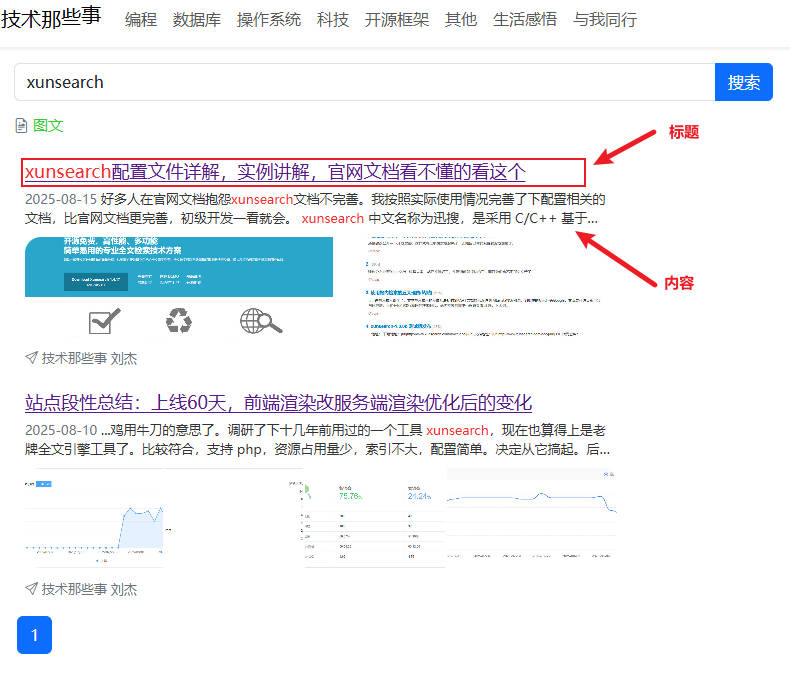
另外提醒一个很重的事,如果你的搜索结果类似我上图的样式,显示结果中只有标题和内容,两个显示字段,那在你设计项目结构的时候,不要建立其他可以搜索的字段,比如 index=both 类型的索引,否则会出现,结果中看到的数据,并没有发现搜索关键词。原因很可能就是搜到了那个不会用来显示的字段。
所以一般这种结构,除了标题就是标题,内容里面,可以将跟此内容有关的所有需要搜索的数据都放置到一个字段中。这样看起来结果就更合理些。当然如果你的显示内容除了标题,和内容部分,还有多个区域,那可以根据实际情况加入更多的索引字段。只要有数据匹配就会显示出来。