通过自动化测试 WebDriver 协议,完美越过防采集
- 作者: 刘杰
- 来源: 技术那些事
- 阅读:591
- 发布: 2025-08-28 12:58
- 最后更新: 2025-08-28 12:58
写过采集代码的,都知道,好多网站都有防采集的功能,防采集的方案也是各种各样,但是无非都是通过 js 来实现。主要是因为后端程序对前端代码 javascript 的执行能力有限,不依赖其他的扩展功能比如 google 的 V8 引擎,很难在后端解析 js 的执行结果。
除此之外,即使通过 V8 引擎能够解析 js,要拿到目标数据,也需要研究具体 js 是如何工作的。所涉及的细节非常多。到此,就引出了我们今天要说的主题,如何通过 WebDriver 自动化测试库,来完成数据采集工作?
PHP采集终极解决方案
web 自动化测试工具,如其名字,主要设计用来对网站的 web 页面做功能测试的。而其测试方式,是通过模拟用户在浏览器的操作来完成测试的。这个设计方案本身,就是要通过浏览器来加载目标测试网页,以拿到最终网页的渲染结果。
再回到我们之前说的防采集的网站,无论怎么防御,最终还是得需要将最终结果呈现给用户的。所以它的防采集方案,防的是爬虫,而不是用户。
由以上两个结论,我们能够知道,自动化测试工具是通过浏览器加载渲染最终页面。它的工作方式,跟传统的抓取服务端后端代码的渲染结果不一样。也因此具备了可以执行任何复杂 js 代码的能力,能够跳过所有通过 js 进行防采集功能的限制。
所以我们的爬虫技术就根据此原理来进行编码。目前自动化技术已经形成专门的 W3C 技术标准(WebDriver 远程协议控制),PHP 程序的 WebDriver 开源库,就是早期由 facebook 研发的 WebDriver 库。目前最新的代码库可以通过 composer require php-webdriver/webdriver来安装。
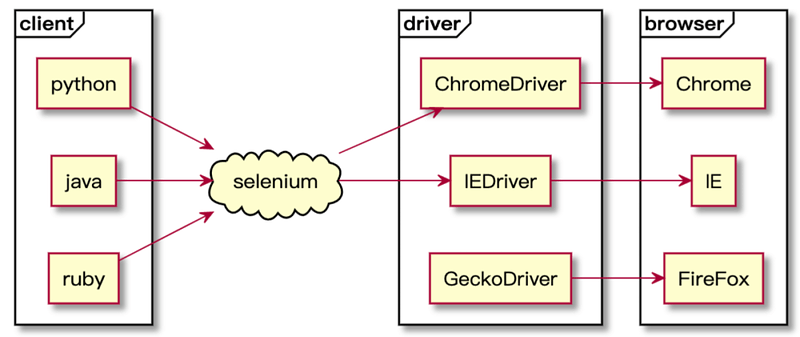
如何通过 WebDriver 驱动浏览器获取目标页面源码
php-webdriver/webdriver 2.0 以上的版本,是需要 PHP 8.0 以上版本支持的。这个要注意,php7.4 支持版本,最新的只能到 1.15(具体参见 composer 官网库)。
获取 RemoteWebDriver 实例
php
$host = 'http://selenium:4444/wd/hub';
// 配置浏览器参数
$chromeOptions = new ChromeOptions();
if ($options) {
$chromeOptions->addArguments($options);
} else {
$chromeOptions->addArguments([
'--headless=new',
'--no-sandbox',
'--disable-dev-shm-usage',
'--window-size=1280,720',
// 禁用图片加载
'--blink-settings=imagesEnabled=false',
// 禁用 css 加载
// '--disable-css',
// 禁用 js 加载
// '--disable-javascript'
]);
}
$capabilities = DesiredCapabilities::chrome();
$capabilities->setCapability(ChromeOptions::CAPABILITY, $chromeOptions);
// 初始化 WebDriver 实例
$driver = RemoteWebDriver::create($host, $capabilities);
等待目标元素渲染完成
在实际页面访问的时候,由于是通过浏览器进行访问,实际页面的加载速度可能受诸多元素影响。比如目标网站速度太慢,页面图片过多加载过慢,部分 ajax 请求接口过慢等等,都会造成页面加载需要时间等待。但是没有目标的等待,就是浪费时间。所以,这其中有了 wait()->until()语句的出现,用来检测目标元素是否已经达到期望条件。这个语句,可以保证在目标元素出现后,及时响应,继续执行。
php
// 最长等待 10s,直到目标元素出现结束等待。
$driver->wait(10)->until(
// 等待特定渲染元素出现
WebDriverExpectedCondition::presenceOfElementLocated(
WebDriverBy::cssSelector('#result')
)
);
获取页面渲染结果(包括 js 渲染之后的 dom 内容)
拿到页面的渲染结果后,就是从页面找出我们需要的最终的内容,找出这个内容的方式,也决定了后续的两个方案的选择:
通过 WebDriver 自带的 findElement 或者 findElements 来获取一个或者多个目标
php
// 查找页面 id 为 #result 的元素
$driver->findElement('#result');
// 查找页面所有 a 标签元素
$driver->findElements('a')
通过以上代码,可以拿到目标节点的RemoteWebElement对象,可以继续进一步查找内容,或者获取内部的 text 数据等。进而获取到目标数据。
但是如果是做数据采集,这里要注意一个特别重要的问题:findElement/findElements 方法,本质都是通过 WebDriver 协议与 node 节点进行远程通信。所以不宜有太多太频繁的 find 操作产生。否则,会让 node 节点cpu 非常高,而且查找效率会很低(非常低效)。
通过将获取到的 html 页面数据,放到 dom 节点筛选的开源库工具中进行本地数据筛选
获取到渲染页面的源码之后,通过一些开源库的本地数据筛选功能,进行数据过滤。php 常用的有 querypath 和 goutte (由于不用http请求部分,可以直接使用 symfony/dom-crawler,goutte 也是依赖这个)这样效率会有质的提升(至少10倍以上)
php
// 获取渲染完毕后的页面源代码
$html = $driver->getPageSource();
// 将页面html数据初始化为 gottue 中的 Crawler 对象,利用 Crawler 对象,对数据进行本地筛选
$crawler = new \Symfony\Component\DomCrawler\Crawler();
$crawler->addHtmlContent($html);
// 可以通过 css 选择器,注意 css 选择器的支持范围,某些语法不支持
$crawler->filter('cssSelector');
// 或者通过 xpath 选择器进行节点筛选,比 css 选择器语法要全面而且强大
$crawler->filterXPath('xpath语法');
通过此混合方案,能够提升数据采集的效率,只是让自动化测试工具,充当浏览器加载目标页面而已。
其他 Selenium 的核心组件的使用,和 docker 部署,可以参照相关文章。